
Wizard AI: Building a Real-Time AI Answer Engine with AWS + Google Search
Overview
Learn how Wizard AI combines AWS Bedrock, Google Embedded Search, and a RAG pipeline to deliver real-time, reference-backed answers. From idea to MVP

Building Wizard AI: A Smarter, Accountable Answer Engine Using Google Search + AWS AI
Proud to share a project I’ve been hands-on with — Wizard AI – Next GenAI, built at the British Institute of Technology and E-Commerce as part of the Wisdom Program.
What started as an idea in a brainstorm with Professor Farmer is now a live MVP that fuses the power of Google Embedded Search, AWS Bedrock, and custom algorithms — all to give students and researchers a fair shot at quality, reference-backed insights.
What Is Wizard AI?
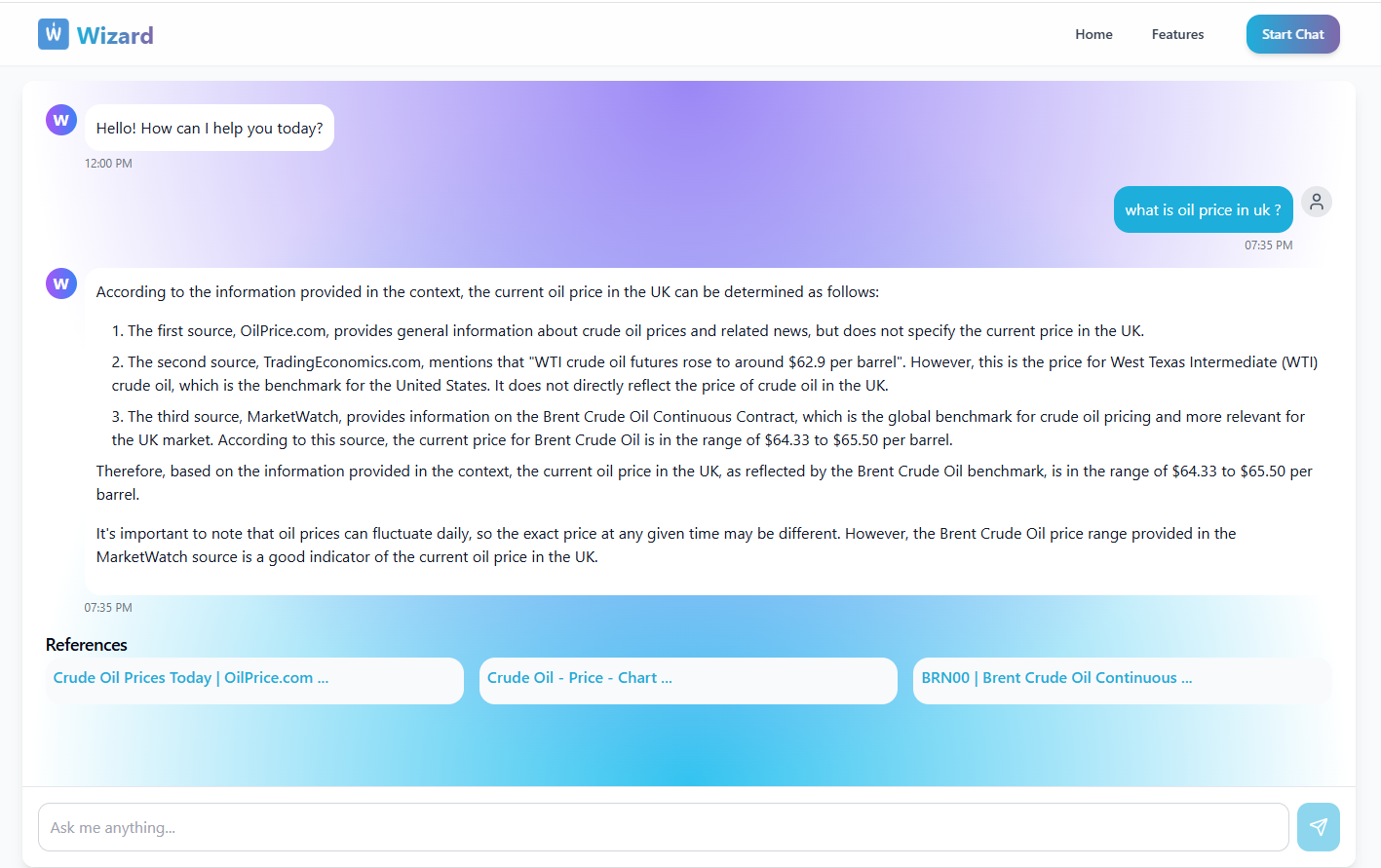
Not just another chatbot. Wizard AI is a real-time answer engine that pulls fresh, credible data from the web, processes it with a low-cost LLM (via AWS Bedrock), and delivers insightful responses — backed by real sources.
We’re basically trying to build a better version of Perplexity AI, tailored for learning, research, and business needs.
The Algorithm Behind It
We built a simple but effective four-step pipeline:
Step 1: Embed the Query
User inputs a question. That query is converted into an embedded text vector for semantic similarity.
Step 2: Fetch Relevant Docs from Google
We use Google Embedded Search to pull in real-time web content related to the query.
Step 3: Generate Insights
Using a low-cost AWS AI model (via Bedrock), we combine the user query with the meta content from retrieved documents to generate reliable, smart answers with RAG.
Step 4: Show Results
The final output — insights + references — are delivered to the user via a slick frontend powered by React.
🛠️ Stack We Used
-
FastAPI (for backend and API gateway)
-
ReactJS (frontend interface)
-
Google Embedded Search API (for live web search)
-
AWS Bedrock (LLM inference on the cheap)
-
Custom RAG Flow (Retrieval Augmented Generation to mix Google data + LLM reasoning)
💡 What I Focused On
I was involved in end-to-end dev — from pipeline design to MVP buildout and production deployment. Fast iterations, quick testing, and just shipping it.
The learning curve? Worth it. Especially understanding how to fuse real-time data with LLMs and keep costs low (token Control) without sacrificing quality.
🔄 Still Evolving
Wizard AI is live now — check it out: https://wizard.net.co/
But we’re not done. We're testing new features, improving data quality, and adding AI agents to support more business use cases.
✅ Looking for contributors — if you're into LLMs, RAG, or full-stack AI systems, hit me up.
Let's Connect

Utsav Gohel
Cloud Architect & Full Stack Developer
Sponsored
Advertisement Space